
どうもです、タドスケです。

こちらの記事のやりかたで、個人ノートの Google ドライブ移行を進めています。
個人の価値観や好きなものなどをまとめたファイルを移行していたときに、ふと…

過去のブログ記事を渡したら、Gemini に僕の考えや経験をもっと伝えられるかも?
と思いついたので、このブログ(Wordpress)の過去記事を Google ドライブにまとめてアップしました。
そのときのやりかたをまとめます。
WordPress の投稿をエクスポートする
まずは WordPress の記事を取得する必要があります。
一件ずつダウンロード…というは、記事の量もそれなりになってきたので避けたいところ。
調べてみたところ、Wordpress の管理画面 → ツール → エクスポート でできることがわかりました:
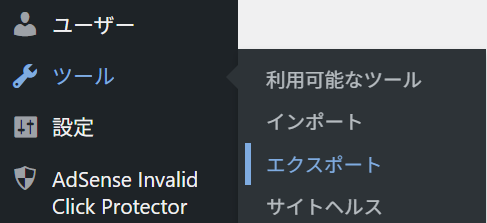
「エクスポートする内容を選択」の欄で、「投稿」を選択してエクスポート:
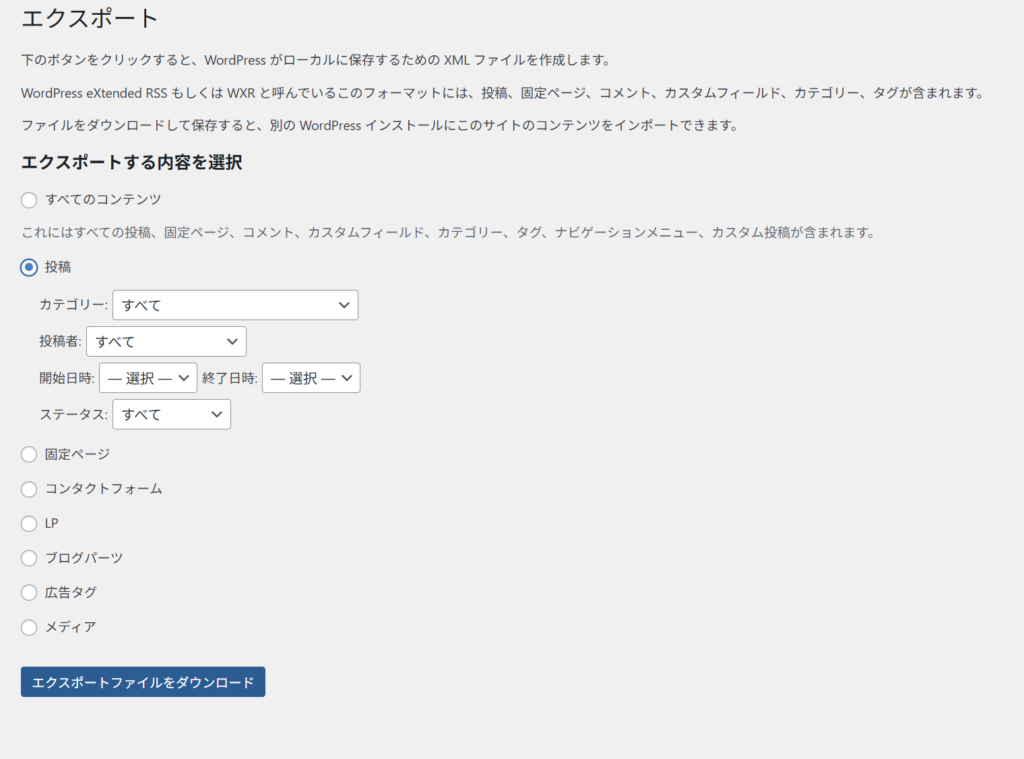
エクスポート結果は、一つの xml ファイルとして保存されます:

xml ファイルから、記事ごとに .docx ファイルを生成する
ダウンロードした xml ファイルをそのまま Google ドライブに入れても、Gemini なら読んでくれそうですが、できれば記事ごとにファイルを分割したほうが、管理しやすいです。
調べてみたところ、Google App Script(GAS)でできそうですが、前回の記事でも書いたとおり、GAS には一日当たりのファイル生成数制限があるので、今回のような大量一括生成には使えなさそう。
オフラインで実行できるスクリプトを作れないか Gemini に相談したところ、以下の手順を提案してくれました:
- Python スクリプトを使い、xml ファイルから一旦 .docx ファイルを抽出する
- GoogleDoc ファイルをオフラインで生成する方法は無いらしい?
- .docx(Office の Word ファイル)なら、アップロード時に Google ドライブ側で変換してくれる(事前設定が必要)
- .docx ファイルを Google ドライブに手動でまとめてアップロードする
Python スクリプトも生成してくれました:
生成された Python スクリプト
import xml.etree.ElementTree as ET
import os
import re
from docx import Document
# --- 設定 ---
xml_file_path = '過去記事 ~20251227.xml' # WordPressからエクスポートしたXMLのパス
output_dir = 'G:/マイドライブ/00_Inbox' # Google Drive同期フォルダのパス
# ------------
def sanitize_filename(filename):
"""ファイル名として使えない文字(\ / : * ? " < > |)を置換"""
if not filename:
return "untitled"
return re.sub(r'[\\/:*?"<>|]', '_', filename).strip()
def clean_html(raw_html):
"""簡単なHTMLタグの除去と整形"""
# <p>, <br> タグを改行に変換
cleantext = re.sub(r'<(p|br\s*/?)>', '\n', raw_html)
# その他のタグを除去
cleantext = re.sub(r'<[^>]*>', '', cleantext)
# 連続する改行を整理
cleantext = re.sub(r'\n\s*\n', '\n\n', cleantext)
return cleantext.strip()
def convert_wp_xml_to_docx():
# 出力フォルダの確認
if not os.path.exists(output_dir):
try:
os.makedirs(output_dir)
print(f"フォルダを作成しました: {output_dir}")
except Exception as e:
print(f"出力フォルダの作成に失敗しました: {e}")
return
# XMLの解析
try:
tree = ET.parse(xml_file_path)
except FileNotFoundError:
print(f"XMLファイルが見つかりません: {xml_file_path}")
return
except Exception as e:
print(f"XMLの読み込みに失敗しました: {e}")
return
root = tree.getroot()
# WordPressコンテンツ用の名前空間
ns = {'content': 'http://purl.org/rss/1.0/modules/content/'}
# 記事(item)をすべて取得
items = root.findall('.//item')
print(f"合計 {len(items)} 件の記事を処理します...")
success_count = 0
skip_count = 0
for i, item in enumerate(items):
try:
title_element = item.find('title')
title = title_element.text if title_element is not None else f"No_Title_{i}"
content_element = item.find('content:encoded', ns)
content_raw = content_element.text if content_element is not None else ""
# コンテンツのクリーンアップ
clean_content = clean_html(content_raw)
# Wordドキュメントの作成
doc = Document()
doc.add_heading(title, 0) # タイトルを大見出しとして追加
doc.add_paragraph(clean_content)
# ファイル名の設定と保存
safe_title = sanitize_filename(title)
file_path = os.path.join(output_dir, f"{safe_title}.docx")
try:
doc.save(file_path)
success_count += 1
if success_count % 10 == 0:
print(f"{success_count} 件完了: {safe_title}")
except Exception as e:
print(f"[スキップ] 保存失敗 ({title}): {e}")
skip_count += 1
except Exception as e:
print(f"[スキップ] 記事の処理に失敗 (インデックス {i}): {e}")
skip_count += 1
print(f"\n処理完了!")
print(f"成功: {success_count} 件、スキップ: {skip_count} 件、合計: {len(items)} 件")
print(f"保存先: {output_dir}")
if __name__ == "__main__":
convert_wp_xml_to_docx()スクリプトを実行すると、ローカルに大量の .docx ファイルが生成されていきます。
いくつかエラーになったファイルがありましたが、こちらは投稿に含まれていた画像などのバイナリファイルのようなのでスキップしました。
docx ファイルを Google ドライブにアップロードする
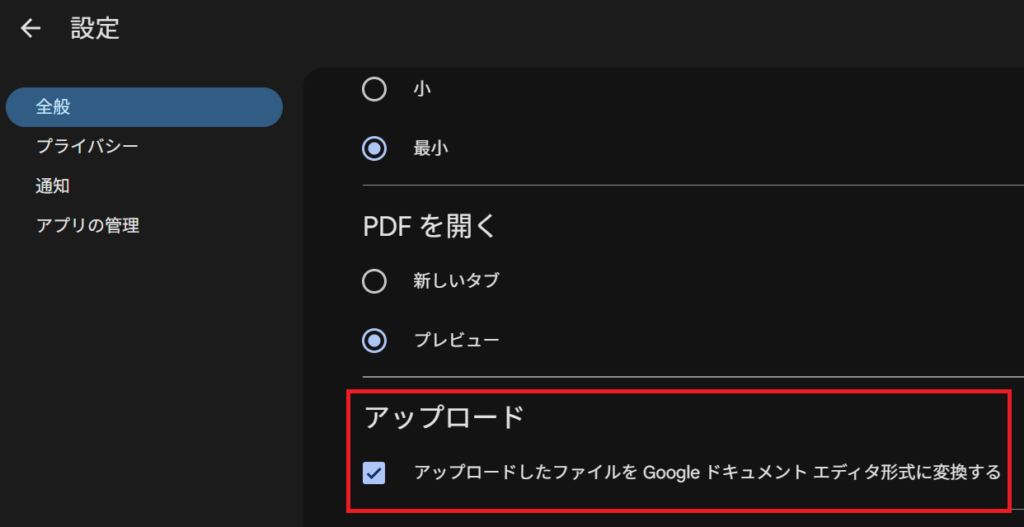
docx ファイルを Google ドライブにアップロードする前に、Google ドライブ側の設定を変更します。
Google ドライブの設定 → 全般 → 「アップロードしたファイルを Google ドキュメント エディタ形式に変換する」のチェックボックスを ON にします。
あとは生成済みの docx を全選択して、Google ドライブにドラッグ&ドロップするだけ。
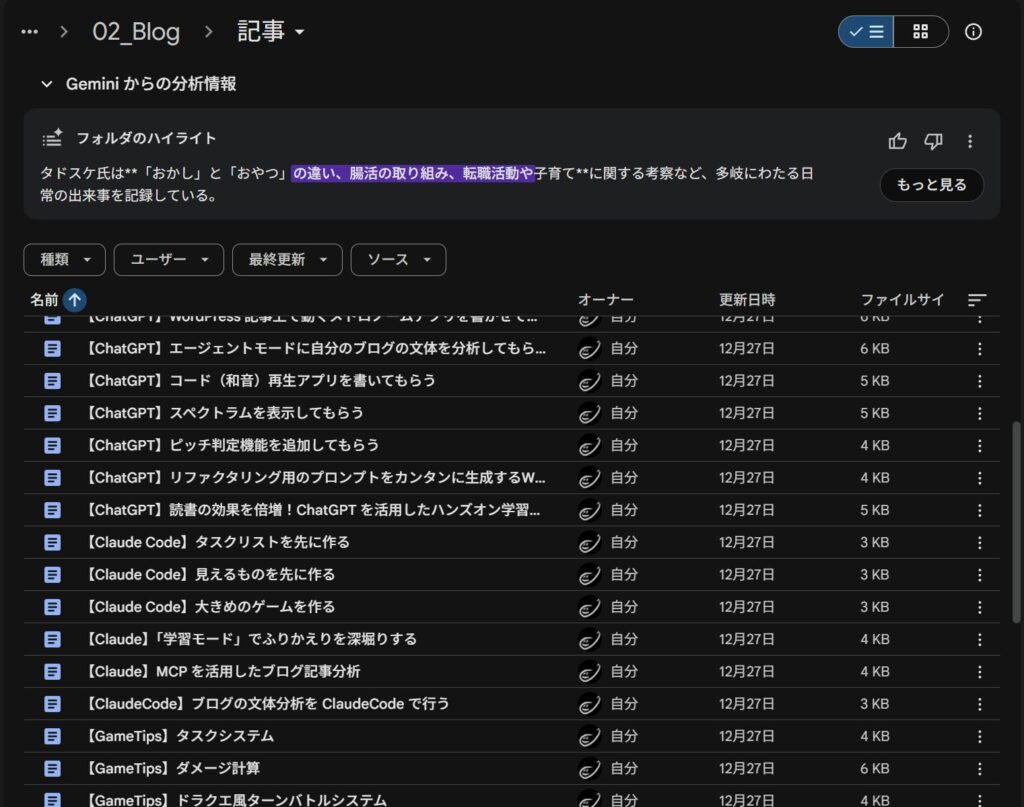
さっそく「フォルダのハイライト」欄に AI の要約メッセージが表示されています。
Gemini に聞いてみる
ドライブにアップロードした記事を、Gemini が拾ってくれるのかを確かめます。
先に、アップロードしたフォルダのパスを毎回していしなくても Gemini が参照してくれるように、「ブログ記事はここに置いてあるよ」という旨のカスタム指示を追加しておきます:

質問する際には「@Google ドライブ」を付け、「ブログを参考に」と添えて質問します。
以下のように回答してくれました:

情報の集約と活用
Google ドライブにブログの過去記事をまとめてアップロードし、Gemini で活用できるようになりました。
自分がこれまで積み上げてきたものが、AI によってより価値のある資産に変わった感じがしてワクワクしています♪
できれば記事を書いた時点で同期してくれる仕組みがあるとなお良いので、そちらについては調べてみます。






コメント